Introduction
Fleak is a managed data workflow platform for building distributed data pipelines using a DAG builder UI, with support for source connectors, processing nodes, and multiple sink destinations.
Fleak is a managed data workflow platform for building, deploying, and running distributed data workflows. Users design workflows in the DAG builder UI by configuring source connectors, adding processing nodes, and defining sink destinations. Once deployed to Fleak's compute cluster, workflows run asynchronously for high-throughput distributed processing.
Fleak handles parallelization and concurrency automatically, optimizing performance across all nodes without requiring users to manage multithreading or load balancing. Workflows can write to various third-party data storage systems, making Fleak production-ready for enterprise applications.
If you need additional help, or think there is something we've missed in the documentation, please contact us at
support@fleak.ai
Key Concepts
Workflow
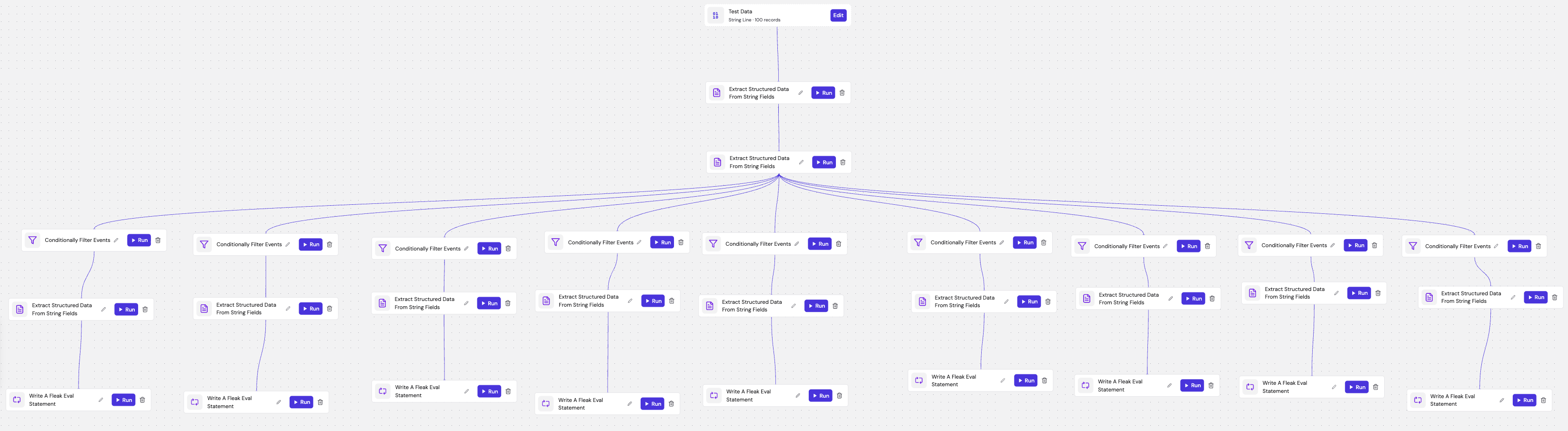
A workflow is the complete data processing flow a user creates to transform data from source to destination by connecting various processing nodes in a sequence. Users build workflows in the Fleak DAG builder UI by:
- Configuring source connectors - Define where data is read from
- Adding processing nodes - Transform and enrich data through the workflow
- Setting sink destinations - Specify where processed data is written
Once published, workflows are deployed to Fleak's compute cluster for distributed, asynchronous processing.
Deployment
After building your DAG in the workflow builder, you can deploy it to Fleak's compute cluster as a fully managed data pipeline. Deployment handles all infrastructure concerns automatically:
- Scalable execution - Fleak provisions the necessary compute resources based on your workflow's requirements
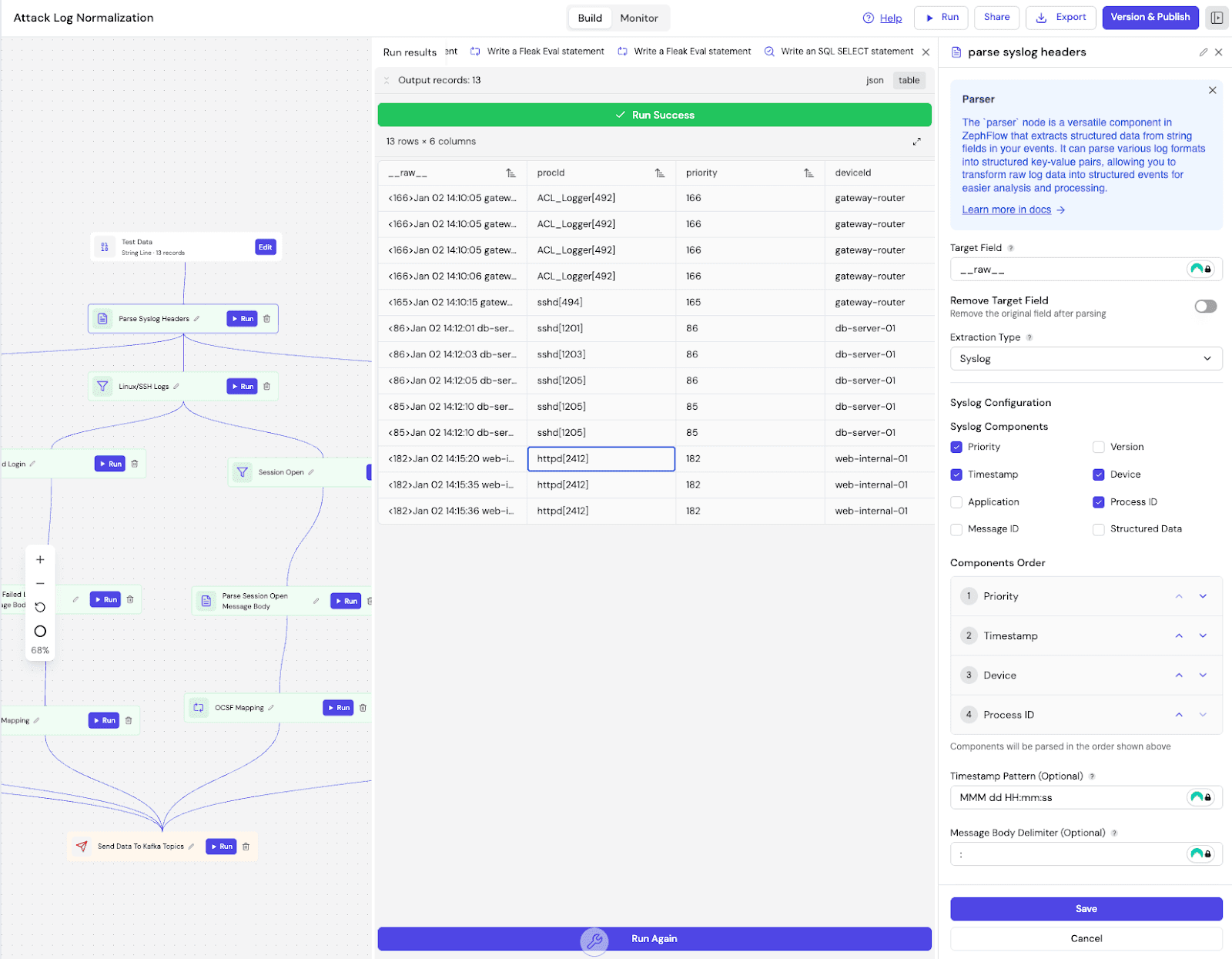
- Monitoring - Track pipeline health, throughput, and errors through Fleak's observability dashboard
To deploy a workflow, click the Deploy button in the workflow builder. Fleak validates your DAG configuration and deploys it to the compute cluster where it begins processing data continuously.
Node
A node on Fleak is a processing module that you can mix and match to build your ideal workflow. Nodes are organized into three categories:
Source Nodes - Define where data is ingested from:
- KafkaSource - Stream data from Kafka topics
- SplunkSource - Query and ingest data from Splunk
Processing Nodes - Transform and enrich data:
- Fleak Eval - Evaluate expressions and transform data (see Fleak Eval Language Spec)
- Filter - Filter records based on conditions
- Assertion - Validate data against rules
- Parser - Parse structured and semi-structured data (JSON, key-value pairs, CSV, Grok, Syslog, CEF, Windows Multiline)
- SQL - Transform data using FleakSQL (see supported SQL syntax)
Sink Nodes - Define where processed data is written:
- KafkaSink - Write to Kafka topics
- DeltaLakeSink - Write to Delta Lake tables
- DatabricksSink - Write to Databricks
Execution Model
Records
Records are units of data that flow through the nodes in the DAG along the edges. Each upstream node's output becomes the input of its downstream nodes, creating a continuous data processing flow from source to sink. A record can vary in size and structure, from a simple string or row to a complex JSON object. In streaming systems, records are often referred to as events.
Data Flow:
- Source nodes ingest data and emit records into the DAG
- Processing nodes receive records, apply transformations, and pass results downstream
- Sink nodes receive the final processed records and write them to the configured destination