Mapping Text Logs
Transform unstructured text logs into OCSF format by configuring parser chains that progressively extract structured data, supporting Grok, Syslog, CEF, Windows Multiline, and other parsing patterns.
What are Text Logs?
Text logs are unstructured log entries that need to be parsed before they can be mapped to the OCSF schema. These logs typically come from:
- System logs
- Application logs
- Security device logs
- Network device logs
- Custom application logs
Creating a Mapping from Text Logs
To create a new mapping from text logs:
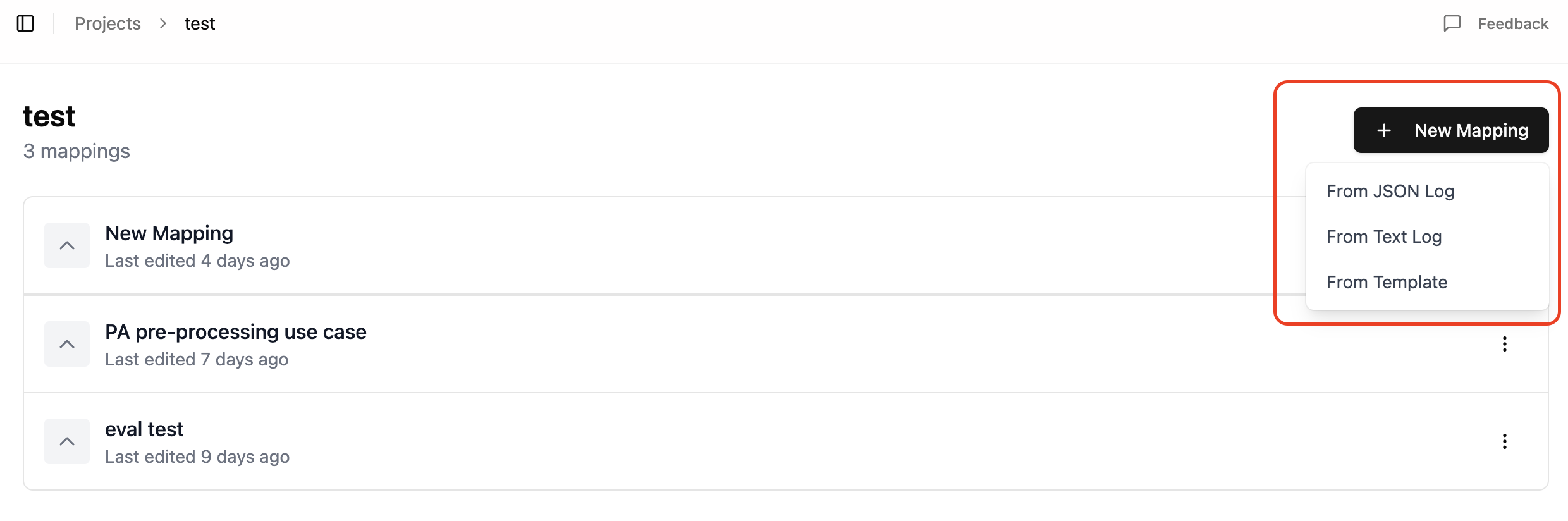
- Click the "New Mapping" button from your project dashboard
- Select "From Text Log" from the options presented
Working with Text Logs
When working with text logs, you have two options for input:
- Paste Text Logs: Directly paste your text logs into the input area. The text area takes an individual log entry.
If you have multiple log entries, use the
+ Add Logbutton. - Upload Text File: Upload a
.txtor.logfile containing your text log. Each uploaded file is treated as a single log entry. You can also drag and drop files into the input area.
Text Log Requirements
For successful mapping, your text logs should:
- Be consistent in format
- Include all relevant security record information
- Be in a readable format (not binary or encoded)
Parser Configuration
The parser configuration screen allows you to create a chain of parsers to progressively extract structured data from complex logs. This multi-stage parsing approach is particularly useful for logs with multiple format layers, such as syslog headers followed by application-specific content.
Parser Chaining
The parser UI supports stacking multiple parser configurations vertically to form a processing chain:

Key concepts in parser chaining:
- Sequential Processing: Each parser takes input from the upstream parser and produces output for the downstream parser
- Target Field: Specifies which field from the previous parsing step will be processed by the current parser
- Parser Types: Different parser types can be combined in a single chain (e.g., Syslog followed by Grok)
You can add additional parsers to the chain by clicking the "Add Parser" button.
Supported Parser Types
The app supports these parser types for each step in your parsing chain:
- Windows Multiline
- Grok
- CEF (Common Record Format)
- JSON
- Text Delimited (CSV, TSV etc.)
- Syslog
- Key-Value Pair
Example: Multi-Stage Parsing
Here's an example of how parser chaining works with a Cisco ASA log:
Original Log:
Oct 10 2018 12:34:56 localhost CiscoASA[999]: %ASA-6-305011: Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256
Parser 1: Syslog Header
- Target Field:
__raw__(the original log) - Parser Type: Syslog
- Syslog Components:
TIMESTAMP,DEVICE,APP - Timestamp Pattern:
MMM dd yyyy HH:mm:ss - Message Body Delimiter:
: - Result:
{
"appName": "CiscoASA[999]",
"deviceId": "localhost",
"content": "%ASA-6-305011: Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256",
"timestamp": "Oct 10 2018 12:34:56",
"__raw__": "Oct 10 2018 12:34:56 localhost CiscoASA[999]: %ASA-6-305011: Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256"
}
Parser 2: Cisco ASA Header
- Target Field:
content(from Parser 1 output) - Parser Type: Grok with pattern
%ASA-%{INT:level}-%{INT:message_number}: %{GREEDYDATA:message_text} - Result:
{
"message_text": "Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256",
"level": "6",
"appName": "CiscoASA[999]",
"message_number": "305011",
"deviceId": "localhost",
"timestamp": "Oct 10 2018 12:34:56",
"__raw__": "Oct 10 2018 12:34:56 localhost CiscoASA[999]: %ASA-6-305011: Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256"
}
Parser 3: Message Body
- Target Field:
message_text(from Parser 2 output) - Parser Type: Grok with pattern
%{WORD:action} %{WORD:translation_type} %{WORD:protocol} translation from %{WORD:source_interface}:%{IP:source_ip}/%{INT:source_port} to %{WORD:dest_interface}:%{IP:dest_ip}/%{INT:dest_port} - Result:
{
"level": "6",
"dest_interface": "outside",
"appName": "CiscoASA[999]",
"message_number": "305011",
"__raw__": "Oct 10 2018 12:34:56 localhost CiscoASA[999]: %ASA-6-305011: Built dynamic TCP translation from inside:172.31.98.44/1772 to outside:100.66.98.44/8256",
"deviceId": "localhost",
"source_ip": "172.31.98.44",
"translation_type": "dynamic",
"protocol": "TCP",
"source_interface": "inside",
"source_port": "1772",
"dest_ip": "100.66.98.44",
"action": "Built",
"dest_port": "8256",
"timestamp": "Oct 10 2018 12:34:56"
}
This demonstrates how complex logs can be broken down into manageable parsing steps, with each step building on the results of the previous step.
Parser Configuration Options
Each parser in the chain has its own configuration panel with specific options:
Grok Parser Configuration
The Grok parser is a powerful pattern-matching tool designed to extract structured data from unstructured text logs.

- Target Field: Specifies which field to parse
- Grok Expression: Grok patterns use the format
%{SYNTAX:SEMANTIC}where:SYNTAXis the pattern name (like IP, WORD, INT)SEMANTICis the field name you want to assign the matched value to
For more info about Grok expression, please refer to Grok Basics
Text Delimited Parser
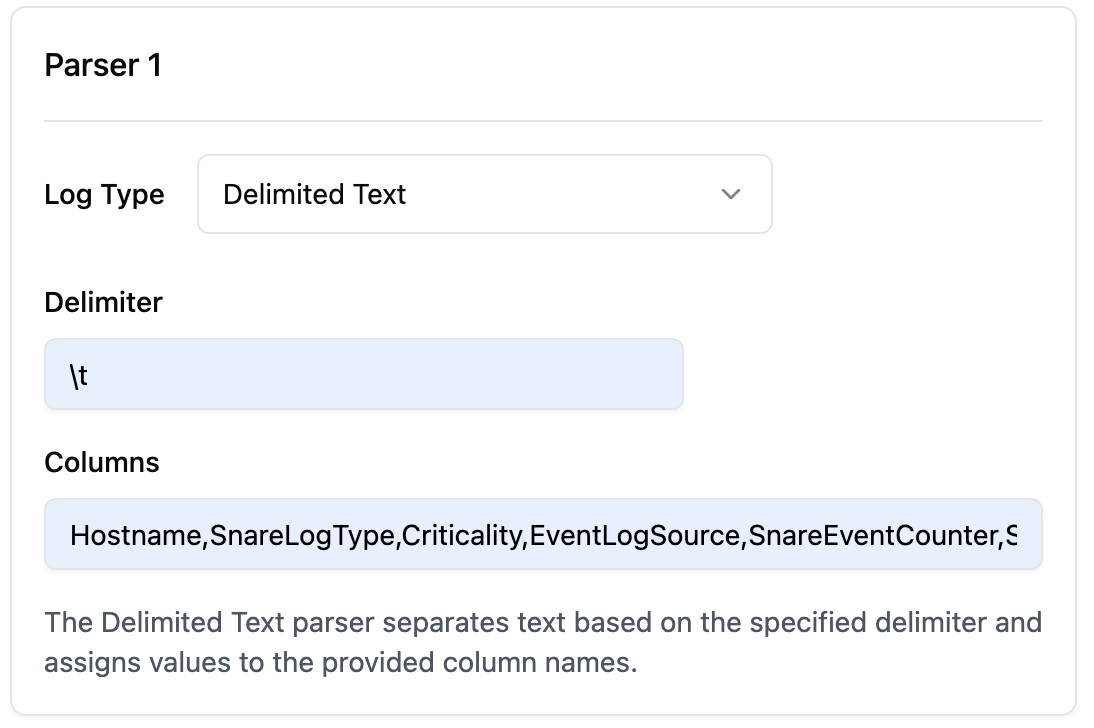
- Target Field: Specifies which field to parse
- Delimiter: Character(s) used to separate values (e.g., comma, tab, pipe)
- Columns: Names to assign to the extracted values
JSON Parser
The JSON parser treats the value in the target field as a stringified JSON and automatically parses it back to a JSON value
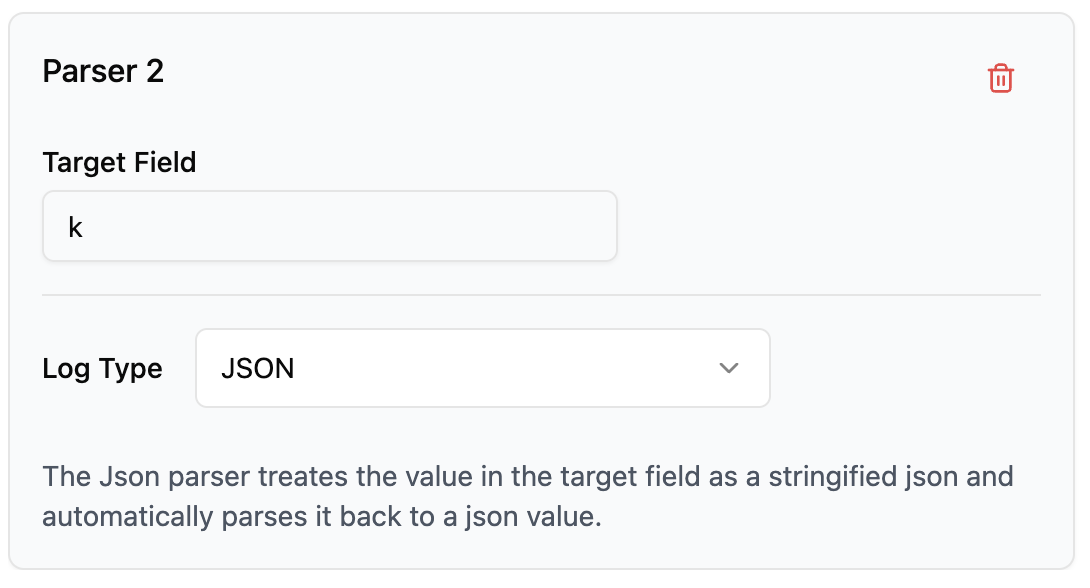
- Target Field: Specifies which field contains JSON to parse
Syslog Parser
The Syslog parser is designed specifically for extracting structured information from logs that follow the Syslog
format, commonly used by system services, network devices, and security applications.
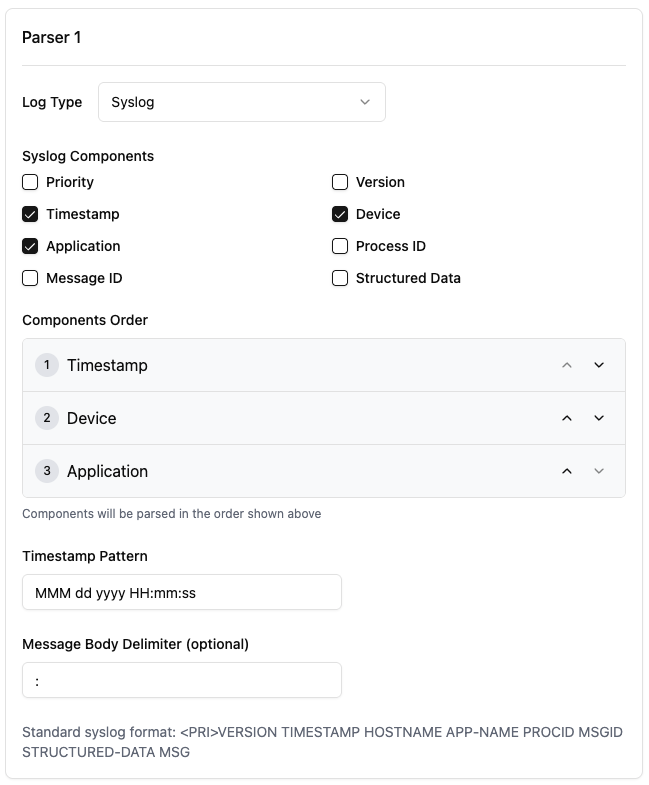
Syslog Components
Syslog messages follow a standard format that can include various components. You can select which components are present in your logs:
- Priority: Log priority enclosed in angle brackets (e.g.,
<13>) - Timestamp: When the record occurred (e.g.,
Oct 10 2018 12:34:56) - Device: Host name or IP address generating the log (e.g.,
localhost) - Application: Application or process name (e.g.,
CiscoASA[999]) - Process ID: Process identifier number
- Message ID: Message identifier code
- Version: Syslog protocol version
- Structured Data: Additional structured information in RFC5424 format
Check the boxes for components that appear in your logs. Only the selected components will be parsed.
Components Order
The order of components is critical for correct parsing. The parser will extract data based on this specified order.
Timestamp Pattern
If your logs include a timestamp component, you must specify the pattern to correctly parse it:
- Enter the timestamp format using Java DateTimeFormatter patterns
- The example in the screenshot uses
MMM dd yyyy HH:mm:ssfor timestamps like "Oct 10 2018 12:34:56" - Common patterns include:
MMM d HH:mm:ss(for "Oct 10 12:34:56")yyyy-MM-dd'T'HH:mm:ss.SSSZ(for ISO 8601 format)yyyy-MM-dd HH:mm:ss(for "2023-10-15 12:34:56")
Message Body Delimiter
The Message Body Delimiter defines the character that separates the syslog header from the actual message content:
- This field is optional but recommended for accurate parsing
- By default, space is used as the delimiter
- In the screenshot example,
:is used to separate the header from the message body
Windows Multiline Parser
The Windows Multiline Parser is a specialized parser configuration to parse Windows record logs that span multiple lines.
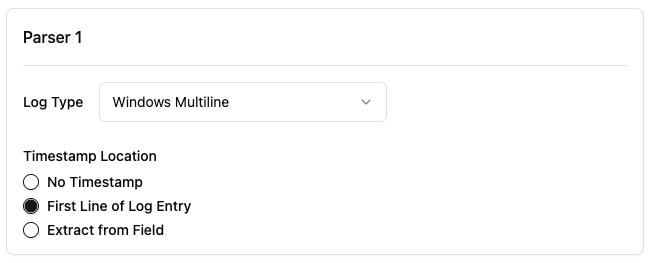
Timestamp Location Types
The parser provides three options for handling timestamps in Windows logs:
| Type | Description | Usage |
|---|---|---|
No Timestamp | Log entries don't contain timestamps | Use when logs don't include timestamps or when timestamp parsing isn't needed |
First Line of Log Entry | Timestamp appears in the first line of each log entry | Common format for most Windows logs |
Extract from Field | Timestamp is found in a specific field | Requires setting Field Name in config |
CEF Parser
The Common Record Format (CEF) parser extracts structured data from logs that follow the CEF format, a widely adopted
standard in security information and record management (SIEM) systems.
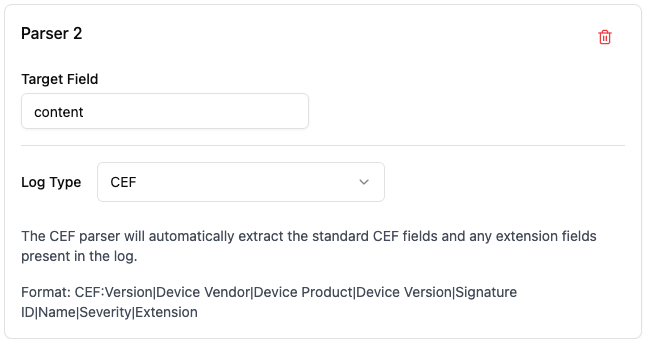
What is CEF?
Common Record Format (CEF) is a standardized log format developed by ArcSight (now part of Micro Focus) that is widely used for security record logging. It provides a consistent structure for security-related records across different vendors and products.
Key-Value Pair Parser
The Key-Value Pair parser extracts structured data from text containing key-value pairs.
- Target Field: Specifies which field to parse
- Pair Separator: Character(s) that separate key-value pairs (e.g., space, comma, semicolon)
- Key-Value Separator: Character(s) that separate keys from values (e.g.,
=,:,>)
For example, parsing key1=value1 key2=value2 with pair separator and key-value separator = produces {"key1": "value1", "key2": "value2"}.
Generating Mapping Rules
After configuring your log parsing, you have two options for creating mapping rules:
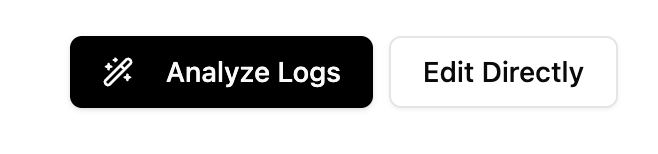
- Analyze Logs: Let the AI generate mapping rules automatically
- Edit Directly: Create mapping rules manually in the editor
AI-Generated Mappings
For AI-generated mappings:
- Provide clear additional context about your logs. This helps the AI understand the log format and generate accurate mappings.
- Click "Analyze Logs" to begin the process
- The AI will first present several OCSF class options that might match your log type
- Select the most appropriate class for your logs
The quality of the additional context greatly determines the AI accuracy. Make sure you provide clear and comprehensive explanation or specs about the sample logs. Formatting the context is NOT important.
Editing Mapping Rules
The mapping editor presents three main tabs:
- Rules: Displays and allows editing of the mapping rules
- Logs: Shows sample logs and their mapped output
- Parser Config: Allows editing of the parser configuration
Rules Editor
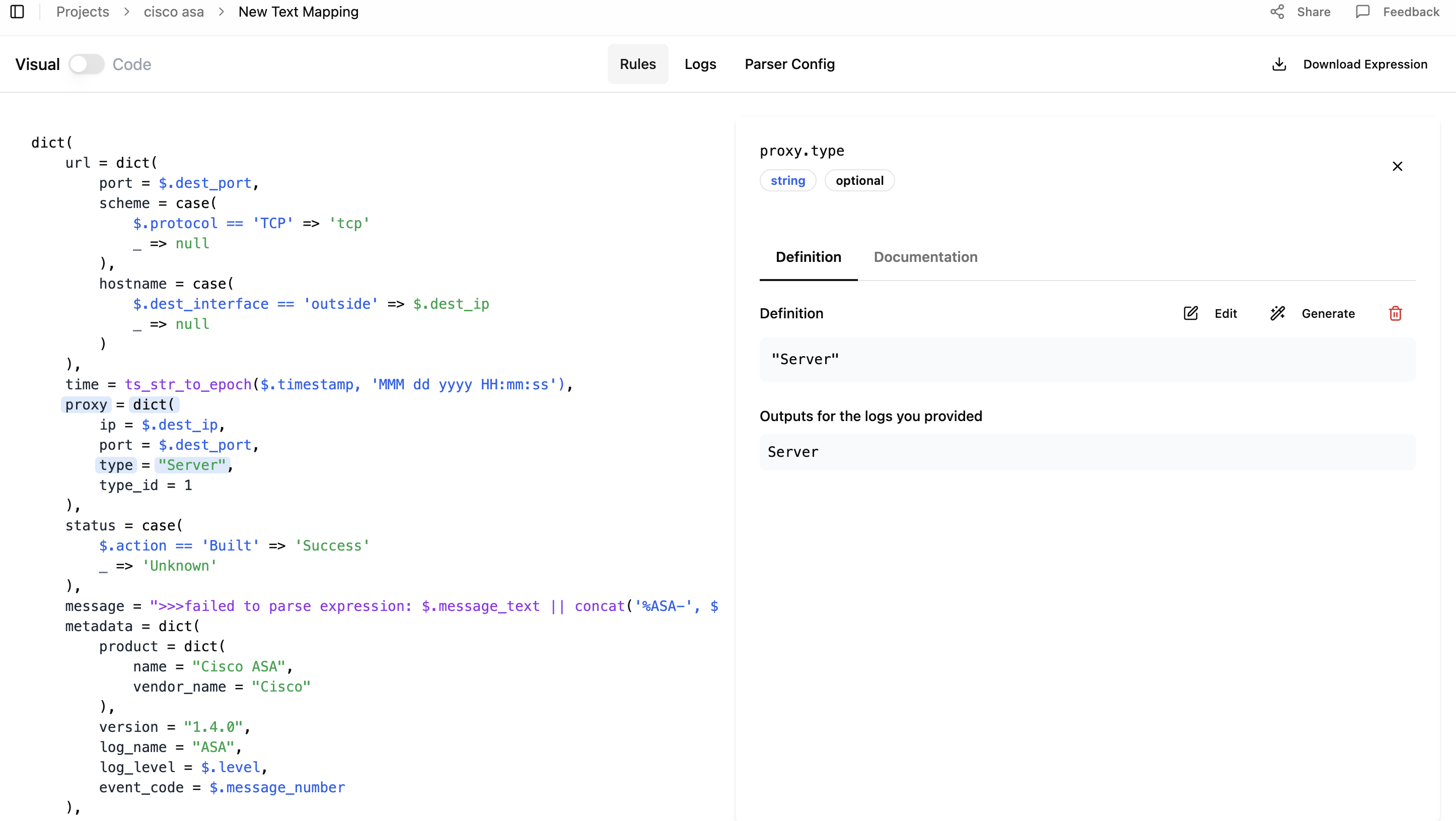
The Rules tab displays mapping rules written in Fleak Eval Expression Language (FEEL). You can edit these rules in two modes:
- Visual Mode: Click on fields to edit them through a user-friendly interface
- Code Mode: Edit the FEEL expression directly in the code editor
The editor provides access to field definitions, documentation, and generation assistance for individual fields.
Logs Tab
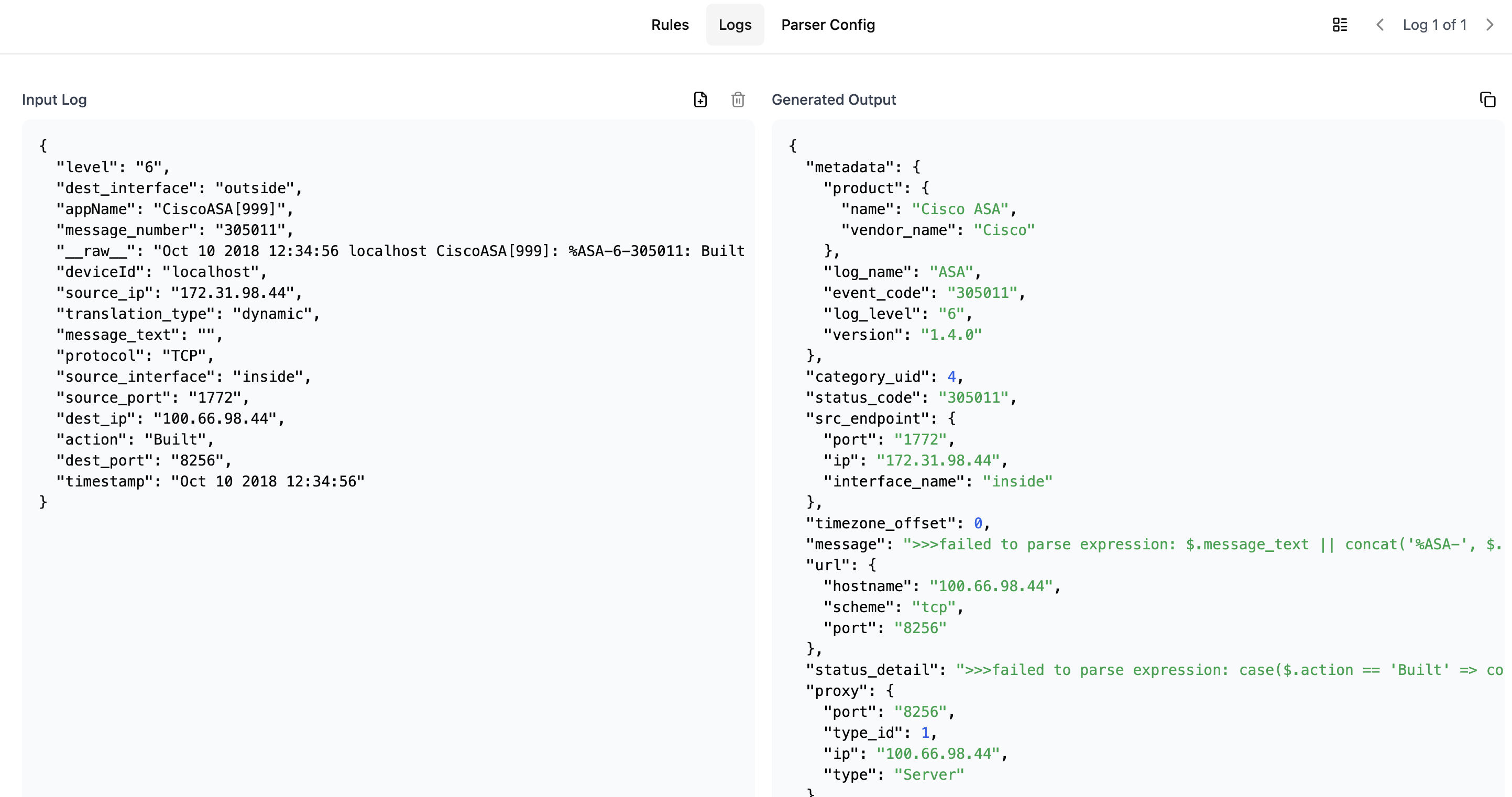
In the Logs tab, you can:
- Add or remove sample log entries using the "+" icon
- View the mapping result for each sample log
- Toggle between individual log view and table view using the icon next to log navigation
Parser Config Tab
The Parser Config tab allows you to review and modify the parser configuration that was created during the mapping setup.
Best Practices for Text Mapping
- Provide Diverse Samples: Include multiple variations of your SAME TYPE text logs to ensure comprehensive mapping
- Check Format Consistency: Ensure log format is consistent across all samples
- Include Context: When using AI generation, provide clear explanations of your log format
- Verify Results: Always review the mapping output for sample logs
- Test Before Production: Validate the mapping with a representative sample set
Downloading and Using the Mapping
Once you've completed your mapping configuration, click the "Download" button in the top right corner of the screen. You can find instructions on different ways of executing the generated rules. To learn more about the ZephFlow execution engine, refer to the ZephFlow Cisco ASA to OCSF tutorial and ZephFlow quick start guide
Need Help?
If you need assistance with text mapping:
- Check the Templates Guide for pre-configured mappings
- Review the JSON Mapping Guide for working with structured logs
- Contact support for assistance with specific log formats